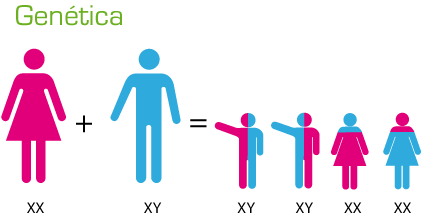
The study of Genetic transmission tell us; how the hereditary characteristics are transmitted? Each individual is unique. Genetics is the branch of biology that studies the transmission of hereditary characters.The similarities and differences are because, each organism has a specific genetic program that is inherited from his ancestors.Each individual is the result of the expression of their genetic information, that is, of all their hereditary characters. As this information is contained in chromosomes, when an individual reproduces, it transmits to its offspring.
Here Is Complete Guide About Genetic Transmission; You Must Know.
GENES.
The term gene was introduced by Johannsen in 1909 to designate the hereditary determinant of a “unit characteristic.” The relationship between gene and enzyme was recognized by Garrod in 1908, but first attained clear definition in the one gene-one enzyme hypothesis proposed by Beadle in 1945. A gene is now often defined as a linear segment of DN’A that codes for a single polypeptide. A more accurate definition of a gene might relate a segment of DNA to a specific molecule of ribonucleic acid (RNA), because there are genes that specify RNAs that do not code for polypeptides, such as ribosomal and transfer RNAs. The sum of all genes of an individual, i.e., the total genetic endowment, is called the genome. The genetic composition of an individual is termed its genotype.
CHROMOSOMES.
The genes are assembled into lengthy linear arrays that together with certain proteins form rod-shaped structures called chromosomes. Normal human nucleated cells, other than germ cells, contain 46 chromosomes, consisting of 23 pairs (diploid state), one of each pair having been derived from each of the individual’s parents.
There are two processes by which genetic information is transmitted to daughter cells. During somatic cell division, called mitosis, identical copies of each chromosome are transmitted to each daughter cell, thus maintaining a uniform genetic composition in all cells of a single organism. By contrast, during the production of germ cells (ova or spermatozoa) a reductive division occurs, called meiosis, with the result that each germ cell contains only 23 chromosomes, representing one copy of each pair of parental chromosomes, one half the usual number (haploid state). The reductive division permits new combinations of chromosomes to occur when ovum and sperm fuse during fertilization to restore the full complement of 46 chromosomes. During meiosis the assortment of chromosomes is random so that each germ cell receives a different combination of maternal and paternal chromosomes.
Independent ascertainment of chromosomes into gametes during meiosis results in an enormous diversity among the possible genotypes of the progeny. For each 23 pairs of chromosomes in the gamete, there are 2M possible combinations, and the likelihood that any one set of parents will produce two offspring with identical sets of chromosomes is one in 2“ or one in 8.4 million (monozygotic twins excepted).
THE GENE AND PROTEIN SYNTHESIS.
In specifying the amino acid sequence of a polypeptide a structural gene first transfers its information to a unique type of ribonucleic acid, known as messenger RNA or mRNA. This RNA is complementary to one strand of DNA, and the sequence of punne and pynmidine bases in the DNA strand determines the base sequence in mRNA, which in turn governs the order of amino acids in the polypeptide. The transfer of information from DNA to RNA involves no change of language (nucleotide -*nucleotide) and is called transcription; the transfer of information from RNA to polypeptide involves a new language (nucleotide —* amino acid) and is called translation.
These relationships are often referred to as the central dogma of molecular biology. Several RNA animal tumor viruses contain an RNA-dependent DNA polymerase (reverse transcriptase) that uses RNA as a template for synthesis of double-stranded DNA, and thus reverses the familiar direction of information flow. The function of this enzyme remains a question of central biologic importance in the problem of neoplasia. Reverse transcriptase is now widely used in the laboratory to synthesize complementary strands of DNA (called cDNA) from isolated molecules of specific MRNA.
DEOXYRIBONUCLEIC ACID.
Deoxyribonucleic acids are linear polymers of deoxyribonucleotides that are formed by phospho-diester linkage between the 5′-phosphate of one nucleotide and the 3′-hydroxyl group of the sugar of the adjacent one. Deoxy-ribonucleotides consist of a purine or pyrimidine base linked to 2-deoxy-D-ribose-5-phosphate. The phosphate confers on DNA its acidic properties.
The purine bases of DNA are adenine (A) and guanine (G); the pyrimidine bases are thymine (T) and cytosine (C). Native DNA consists of two polynucleotide strands wound around each other. The two strands are held together in part by hydrogen bonding between apposing purine and pyrimidine bases; the sugar-phosphate groups form an external spine. The internal bondings are specific. Adenine always pairs with thymine and guanine with cytosine. Thus, the two chains are not identical but are complementary with respect to base pairings, A to T and G to C.
In the replication of DNA during mitosis the parent molecule unwinds and the bases of each strand serve as a template for the synthesis of a new’ strand of DNA. Thus just prior to cell division the cell has a double complement of DNA and of completed chromosomes. Since each chromosome is now represented four times, this is called the tetraploid state. Since both parental strands are conserved in the next generation, each now paired with a newly synthesized complementary partner, replication is termed semi-conservative.
In addition to its primary structure, the DNA in eukaryotic (nucleated) cells is organized into a variety of secondary coils and loops under the influence of basic proteins (histones) that bind to DNA. There are about 50 different histone proteins in the cell, some arginine rich, some lysine rich.
RIBONUCLEIC ACID.
Ribonucleic acids are also linear polymers of nucleotides, but they differ in important respects from DNA. In RNA the sugar is D-ribose-5-phosphate, and the bases are adenine, guanine, cytosine, and uracil (instead of thymine). In addition, all mammalian RNAs are single stranded.
There are four main types of RNA, distinguishable by characteristic composition, size, functional properties, and cellular location. These are giant or heterogeneous nuclear RNA (hnRNA), messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). At any instant, hnRNA and mRNA constitute 3 to 5 per cent of total cellular RNA, rRNA 80 to 85 per cent, and tRNA 10 to 15 per cent of the total. The roles of each of these RNAs are discussed below.
MESSENGER RNA .
The initial product of nuclear gene transcription is a giant molecule of RNA, on the average five to ten times larger than mRNA. The heterogeneous nuclear RNA must be processed to form smaller molecules of functional mRNA before the mRNA leaves the nucleus to associate with a ribosome in protein synthesis. The initial synthesis of hnRNA reflects the transcription of the dispersed structural gene (whose segments are called exons) together with intervening segments of noncoding DNA (introns). The function of the introns is not known. Most of the hnRNA remains in the nucleus and is degraded. The biochemical mechanisms of recognition and excision of mRNA segments and of their reassembly into a functional mRNA are not well understood.
The molecules of mRNA vary in size, depending on the length of the polypeptide chain to be synthesized, and range from 300 to 3000 nucleotides in the coding sequence. They also vary in their stability, with half-lives ranging from minutes to many hours. For example, the half-life of globin mRNA is about 14 hours. Since it requires only 10 to 20 seconds to assemble a polypeptide chain, a single molecule of mRNA may participate in the synthesis of many molecules of protein.
THE GENETIC CODE.
Because most proteins are composed of 20 different amino acids, and because DNA has only four different nucleotide bases, each codon must contain a minimum of three bases (4J – 16; 4J = 64). The DNA and RNA triplet codes for each of the 20 amino acids are known (Table 31-1). The 64 different triplets include 61 that have been shown to code for one of the 20 amino acids, and three that function as chain-terminating codons and do not code for any amino acid. The RNA codons for chain termination are UAA, UAG, and UGA. Two codons (AUG and GUG) serve to initiate polypeptide synthesis as well as to insert amino acids and are sometimes designated chain-initiating codons. Since many ammo acids have more than one codon, the code is said to be degenerate. Each codon, however, is completely specific. Since the same codons code for the same amino acids in all plant, bacterial, viral, and animal systems studied (but see exceptions below, under Mitochondnal DNA), the code is regarded as universal. The nucleotide sequences of human genes disclose alternating sequences of coding and noncoding segments.
The correspondence of the sequences of DNA and RNA codons in the polynucleotides with the sequence of amino acids in the polypeptides confirms the principle of co-linearity of the sequential array of the information in the gene and mRNA and the amino acids of the proteins.
MITOCHONDRIAL DNA A small fraction of cellular DXA is located in the mitochondria and maps as two distinct circular strands. This DN’A contains the codes for certain ribosomal and transfer RNAs used by the mitochondria in protein synthesis, e.g., of cytochrome b and cytochrome c oxidases I, II, and III. Mitochondrial DNA lacks intervening sequences or introns. Its codons differ from those of nuclear DNA or of any present-day prokaryotes in a few instances: UCA = tryptophan (not termination), AUA – methionine (not isoleucine), and ACA and ACC = termination (not arginine).
TRANSFER RNA.
Amino acids must be “activated” before they can be assembled into polypeptide chains. Activation is accomplished by reaction of the amino and with ATP to form an amino acid adenylate. The amino acid adenylate then reacts with a molecule of tRNA to form an aminoacyl-tRNA. Both steps are catalyzed by a single enzyme, an aminoacyl-tRNA synthetase, which is specific for the amino acid as well as for the receptor tRNA. Although only a single aminoacyl-tRNA synthetase exists for each of the 20 amino acids commonly found in proteins, there may be several tRNAs for one amino acid. Each amino acid has at least one specific tRNA. tRNAs are transcribed from DNA by RNA polymerase III.
RIBOSOMES.
The template mRNA and the aminoacyl-tRNAs meet on the ribosome, where assembly of polypeptide chains takes place. Ribosomes are cytoplasmic particles composed of about one half protein and one half RNA. In differentiated mammalian cells most of the ribosomes are found in intimate association with membranes of the endoplasmic reticulum. Smaller numbers are present in the nucleus and mitochondria where a limited amount of protein synthesis also takes place. The number of ribosomes per cell is a rather direct function of the rate of cell growth.
The cytoplasmic ribosome in eukaryotic cells has a molecular weight of 4.5 million. It is composed of a small (40S) and a large (60S) subunit. The 40S subunit contains an 18S rRNA molecule of 2000 nucleotide residues and approximately 30 proteins; the 60S subunit contains both a 28S rRNA of 4000 nucleotides and a 5S rRNA of 121 nucleotides, plus approximately 50 different proteins. Ribosomal RNAs have genes that are duplicated and multiply represented in the chromosome. Ribosomal RNAs are transcribed from DNA by RNA polymerase II. Messenger RNA, bearing the instructions for polypeptide synthesis, forms a complex with the smaller ribosomal subunit and with the initiator aminoacyl-tRNA. The larger subunit then attaches to this complex to form a functional ribosome, and the sequential assembly of amino acids into protein can now begin.
PROTEIN SYNTHESIS.
The translation of mRNA into a polypeptide occurs in three consecutive phases: initiation, chain elongation, and termination.Initiation involves formation of a complex of aminoacyl-tRNA and mRNA on the ribosome. The process is complex and involves in addition at least three initiation factors (cytoplasmic proteins) and GTP. In prokaryotes and in mitochondria of eukaryotes initiation is specific for N-formylmethionyl-tRNA, but the eventual protein does not have a terminal N-formyl-methionine residue. Thus deformylation takes place before release of the protein from the nbosome. In some proteins the terminal methionine is also removed. In eukaryotic cells, initiation of cytoplasmic protein synthesis also involves methionyl-tRNA, but in this instance the methionine is not formylated.
Once polypeptide chain synthesis has been initiated, continuation of the process requires the attachment of the aminoacyl-tRNA of the second amino acid, as specified by the second codon of the mRNA. Peptidyl synthetase now catalyzes the formation of a peptide bond between the first and second amino acids, and the mRNA then moves along the ribosome so that the third amino acid now comes into position with further elongation of the chain. In like manner the entire polypeptide chain is synthesized from the amino-terminal to carboxy-terminal end. The mRNA has a distinct polarity as it moves along the ribosome, always reading from the 5′ to the 3‘ end. When a chain-termination codon (non-sense triplet) is reached, elongation ceases and the polypeptide chain is released from the ribosome.
A single mRNA molecule may move across the surfaces of several ribosomes simultaneously. A cluster of ribosomes attached to a single mRNA strand is called a polyribosome; polyribosomes synthesizing globin chains (MW 17,000) consist, on the average, of four to six ribosomes. A schematic diagram of the genetic control of protein synthesis is shown in Figure 31-1.
MUTATION And Genetic Transmission.
Broadly defined, a mutation is a stable, heritable alteration in DNA. Mutations occur approximately once in 10* replications per gene. Mutations can involve gross alterations in the structure of a chromosome, such as a duplication or deletion, or the translocation of a portion of one chromosome to another. Disorders resulting from mutations of this type are discussed in Ch. 35.
Mutations can also be minute, involving as small a segment of DNA as a single base. When one base is replaced by another, the result is a point mutation. Point mutations may be of three types: (1) a synonymous mutation (making up about 23 per cent of random point mutations), in which the base substitution results in replacement of one codon by another that codes for the same amino acid, as in a change in DNA from GAA—*CAG, both of which code for leucine; (2) a missense mutation (73 per cent of point mutations), in which a base replacement changes the codon of one amino acid to that of another, such as AAG -*AGG, which results in replacement of a phenylalanine by a serine residue; or (3) a non-sense mutation (4 per cent of point mutations, in which the base replacement changes an ammo and codon to one of the terminator codons, such as TTC-*ATC, which results in a reading change from lysine to “stop.” Following a point mutation there is always a finite chance that a second mutation may occur at the site of the original mutation. If such a mutation corrects the genetic change, it is called a reversion.
Deletions or insertions of a single base give rise to frame-shift mutatwns because they alter the reading frame of the genetic code so that every triplet distal to the mutation in the same gene is changed. A frame-shift mutation results in synthesis of a new amino acid sequence beyond the mutation until a stop codon is reached. Frame-shift mutations can be corrected by a second mutation of the opposite type. A single base deletion followed by a single base insertion will restore the onginal code, and the altered ammo acid sequence will be limited to the segment corresponding to the length of coding DNA between the two mutations, unless the first mutation or the frame-shift generates a new stop signal. If the transcribed segment between two mutations is short and does not involve a critical region of the polypeptide, a new protein of normal function may be produced. A second mutation occurring at a new site which corrects the effect of the first, in whole or in part, is called a suppressor mutation.
During the meiotic process, homologous chromosomes pair and exchange genetic material by a process called crossing over. If the pairing is not precisely in register along the entire length of the chromosomes, unequal, or nonhomologous crossing over occurs and results in deletion of genetic material from one chromosome and duplication in the other. Deletions or insertions can involve segments as small as one or two bases, or as large as major segments of two adjacent genes, or even an array of multiple genes involving thousands of bases.
Examples of almost all of these categories of mutations have been discovered among variant human hemoglobins. For example, sickle cell hemoglobin differs from normal hemoglobin in the replacement of a glutamic acid residue by a valine in the sixth position of the (3 chain. The mutation results in a replacement of an A by a U in the RNA codon, GAG -*GUG. Mb McKees-Rock is a 144 residue 0 chain vanant that lacks the last two C-termmal amino acids tyrosine and histidine, as a result of conversion of a tyrosine codon UAU to code, and the altered ammo acid sequence will be limited to the segment corresponding to the length of coding DNA between the two mutations, unless the first mutation or the frame-shift generates a new stop signal. If the transcribed segment between two mutations is short and does not involve a critical region of the polypeptide, a new protein of normal function may be produced. A second mutation occurring at a new site which corrects the effect of the first, in whole or in part, is called a suppressor mutation.
REGULATION OF GENE ACTION.
In mammalian tissues only 10 to 20 per cent of structural genes are transcribed at any time. Different sets of genes are transcribed at different stages of differentiation and in different tissues. One example is hematopoietic cells, which produce first seta and epsilon, or epsilon and alpha, globin chains (embryonic hemoglobins), then a and chains (fetal hemoglobin), then following birth a and (3 chains (adult hemoglobin) and small amounts of a and 6 chains (Hb-A,). Zeta, t, and -y chain production is sequentially turned off. The genes for six globin chains are arranged sequentially in the 5’ to 3′ direction on the short arm of chromosome 11: epsilon-2, epsilon-1, G-gamma, A-gamma, delta, and beta. With advancing development of the fetus and infant, the genes nearer the 5′ terminus are switched off and those nearer the 3′ end switched on.
The basis of differential gene action in mammalian cells is poorly understood. For years histones have been considered candidates as regulatory factors in the expression of genetic information, but this is now considered unlikely. Histones appear to cover only about 20 per cent of DNA at random locations, leaving 80 per cent of the DNA molecule available for interaction with nonhistone proteins and nucleic acids. From reconstruction experiments utilizing acidic chromatin proteins isolated from specific organs, it now appears that nonhistone proteins recognize specific sequences in the DNA molecule and that the specificity of gene expression resides in the acidic chromatin proteins, rather than the histones.
Certain hormones have a profound effect on specific gene expression in mammalian systems. Clucocorticoids first bind to a cytoplasmic receptor, and the hormone-receptor complex then enters the nucleus, where it attaches to chromatin and induces specific protein synthesis. Triiodotyrosine, by contrast, binds directly to a nuclear receptor prior to inducing gene expression through an influence upon the activity of DNA-dependent RNA polymerase and the rate of RNA synthesis.
Azacytidine has recently been found to stimulate fetal hemoglobin production in man. This effect may be beneficial in (3-thalassemia and sickle-cell disease. The action of azacytidine is so prompt that it may involve an effect on processing of a giant RNA transcript rather than on gene expression.
Genetic information is transmitted from one generation to the next through the process of inheritance. To illustrate this in a tabular format, let’s focus on some key concepts and stages.
- DNA Replication: Before a cell divides, its DNA is replicated so that each new cell will have a complete set of genetic information.
Process Description DNA Unwinding The DNA double helix unwinds. Base Pairing Free nucleotides pair with complementary bases on each DNA strand. Formation of New Strands Two new DNA molecules are formed, each with one old strand and one new strand. - Gene Transmission during Reproduction:
Type Description Sexual Reproduction Involves the fusion of gametes (sperm and egg). Each gamete contains half the genetic material of the parent. Asexual Reproduction Involves a single organism or cell. The offspring are genetically identical to the parent. - Mendelian Genetics:
Concept Description Genes Units of heredity found on chromosomes. Alleles Different forms of a gene. Dominant Allele An allele that masks the effect of another allele. Recessive Allele An allele whose effect is masked by a dominant allele. Genotype The genetic makeup of an organism. Phenotype The physical expression of the genotype. - Chromosomal Basis of Inheritance:
Event Description Meiosis A type of cell division that reduces the number of chromosomes in the parent cell by half and produces four gamete cells. Crossing Over Process during meiosis where two chromosomes pair up and exchange segments of their genetic material. Independent Assortment The random distribution of the pairs of genes on different chromosomes to the gametes. - Molecular Genetics:
Process Description Transcription The process of copying a segment of DNA into RNA. Translation The process where ribosomes create proteins based on the sequence of an RNA molecule. Mutation Permanent alteration in the DNA sequence that makes up a gene. - Modern Genetics:
Area Description Genetic Engineering Direct manipulation of an organism’s genes using biotechnology. Genomics The study of genomes, the complete set of genes in an organism. CRISPR-Cas9 A technology for editing genomes, allowing the addition, deletion, or alteration of genetic material.
This table offers a simplified view of the complex process of genetic transmission and should be complemented with detailed study for a more comprehensive understanding.
Conclusion
Understanding how genetic information is transmitted is a fundamental step towards unraveling the mysteries of life. The complex interplay of genetic principles, inheritance patterns, and disease susceptibility showcases the intricate nature of our genetic makeup. By continuing to expand our knowledge in this field, we pave the way for groundbreaking advancements in medicine, genetics, and personalized healthcare.